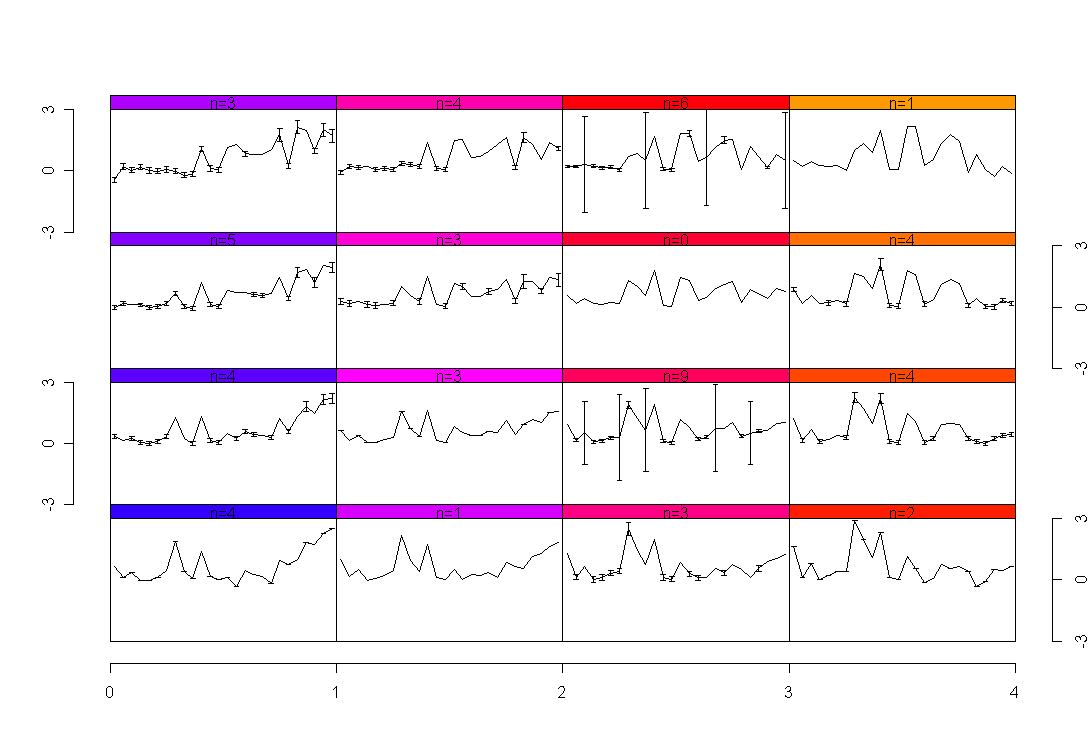
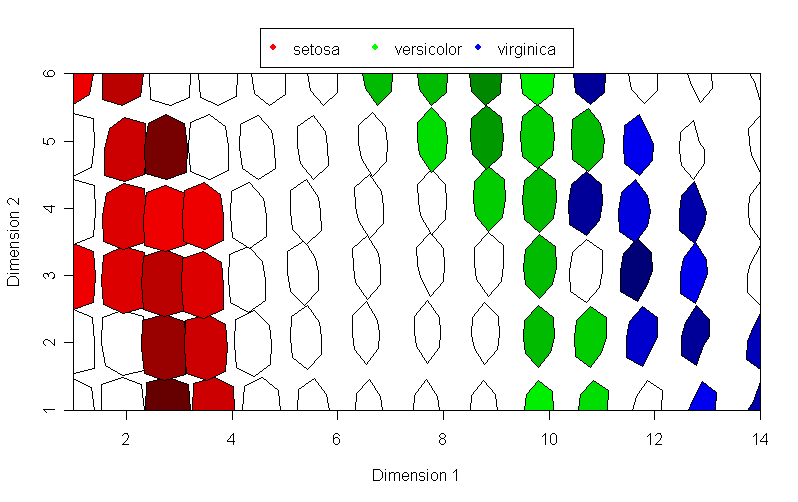
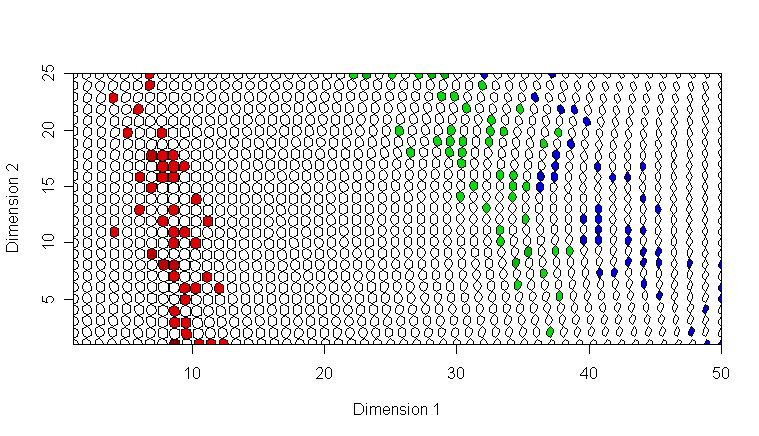
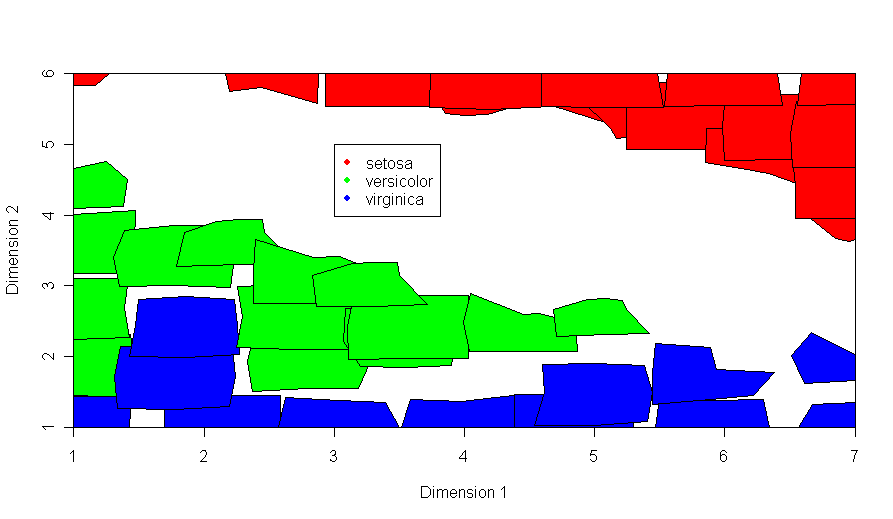
SOM + genes
Interpreting patterns of gene expression with self-organizing maps: methods and application to hematopoietic differentiation.
-> [pdf]
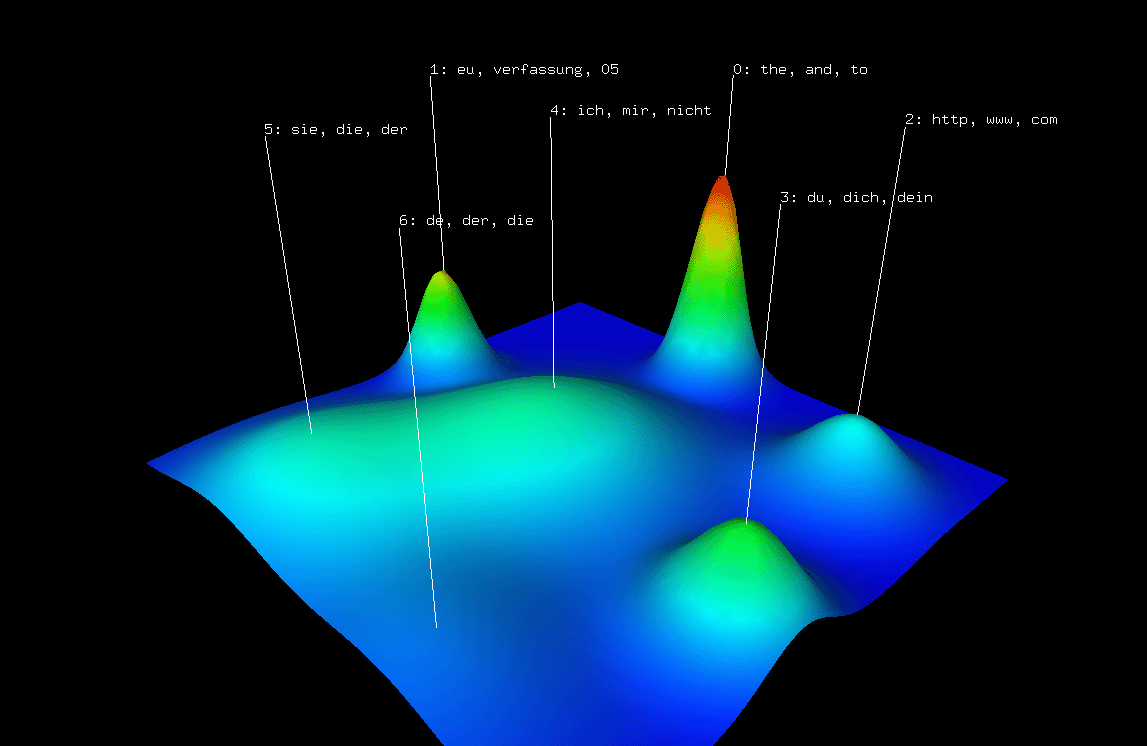
to provide an ‘‘executive summary’’ of a massive data set
by extracting the n most prominent patterns (where n is the
number of nodes in the geometry) and arranging them so that
similar patterns occur as neighbors in the SOM. As with all
exploratory data analysis tools, the use of SOMs involves
inspection of the data to extract insights.
SOMs are widely used in data mining because they have
many desirable mathematical properties, including scaling well
to large data sets. In our own hands, we have indeed found
them valuable in analyses involving hundreds of experiments.
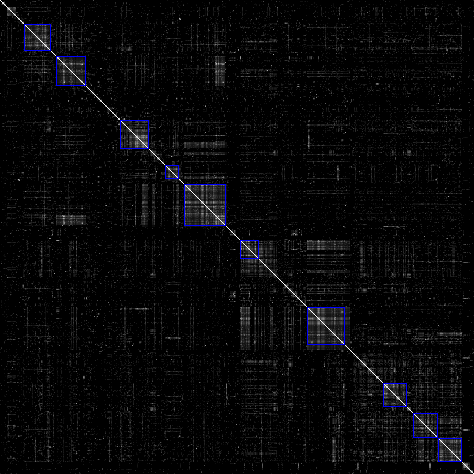
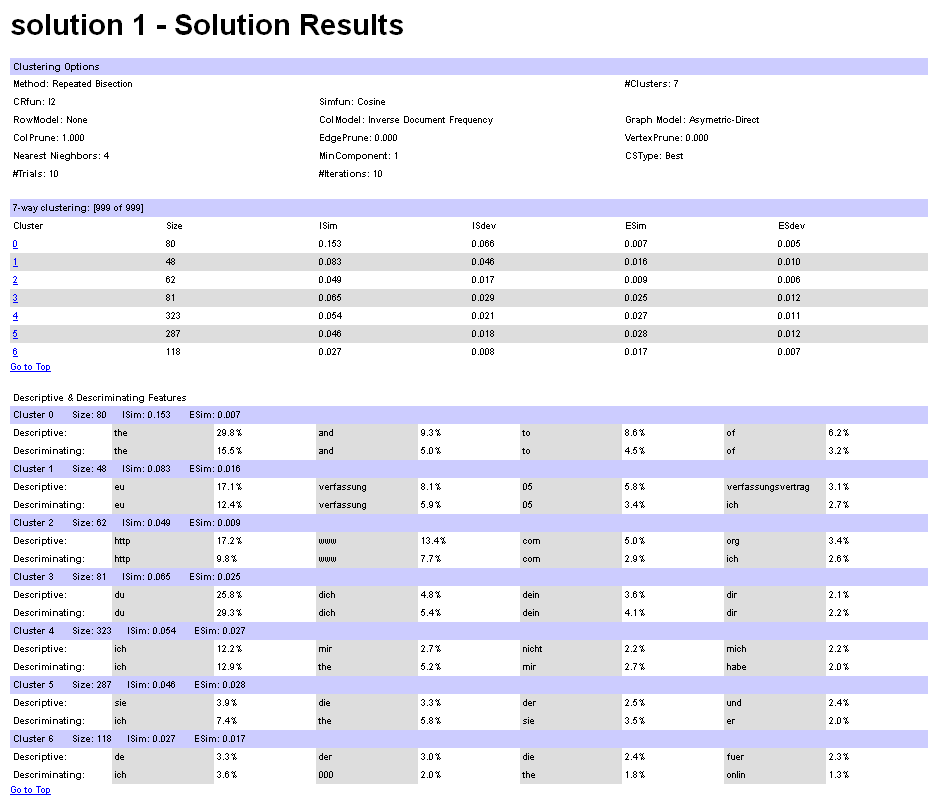
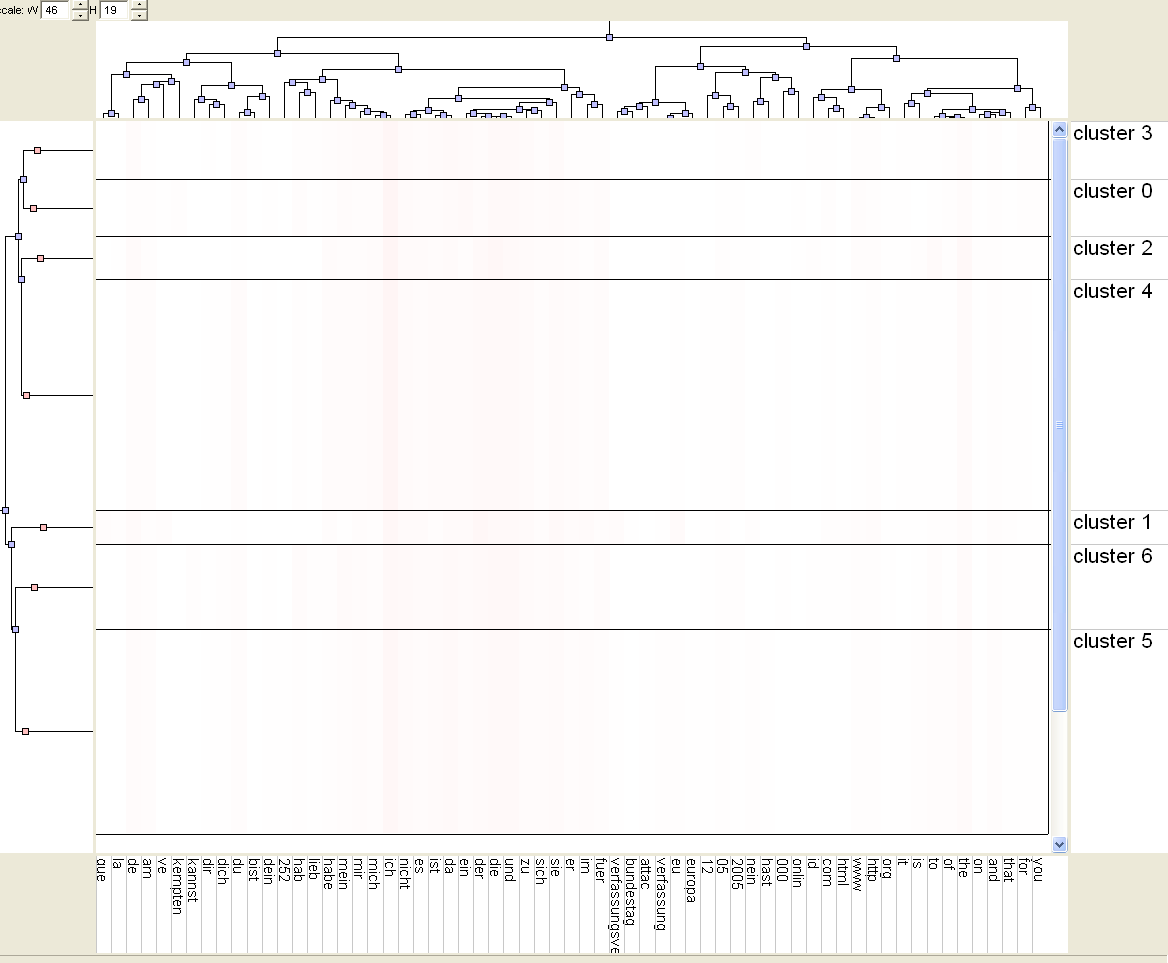
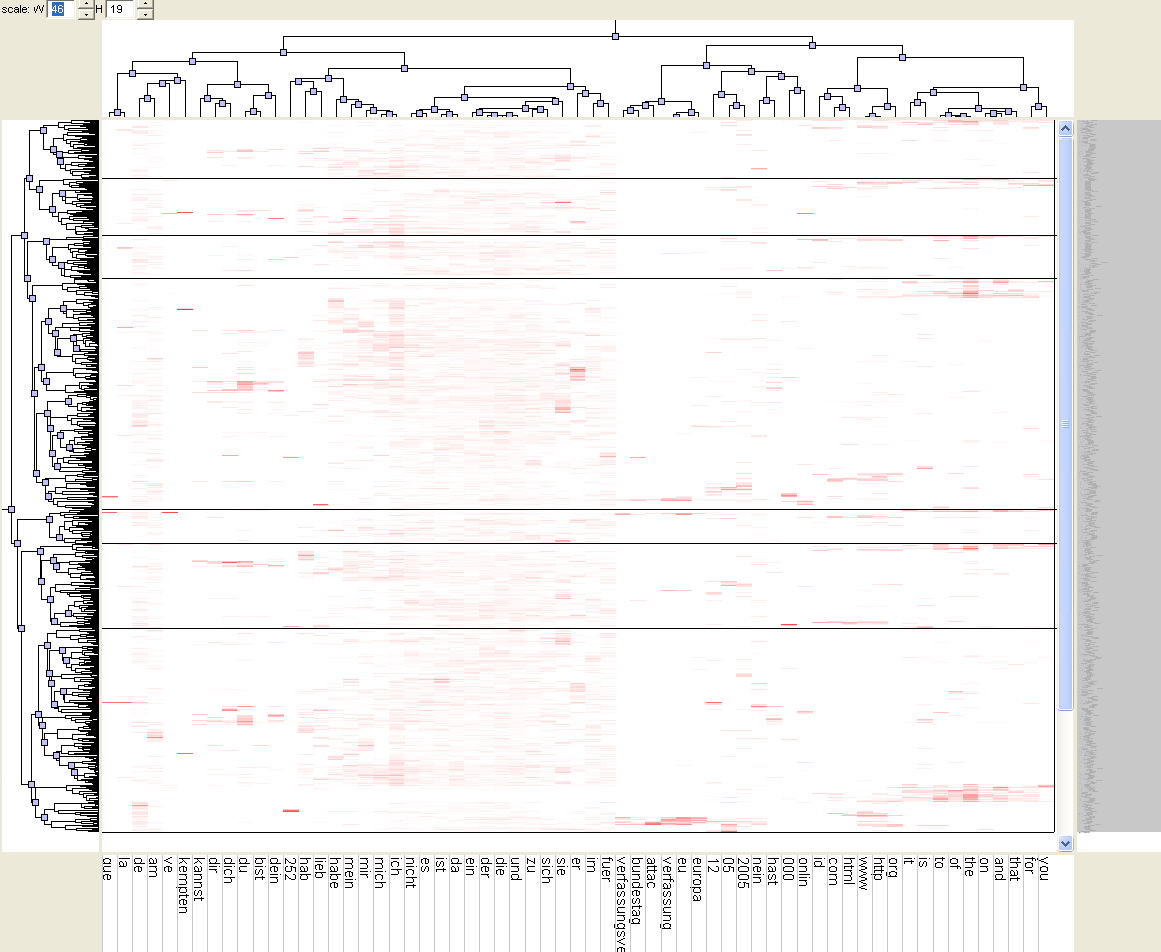
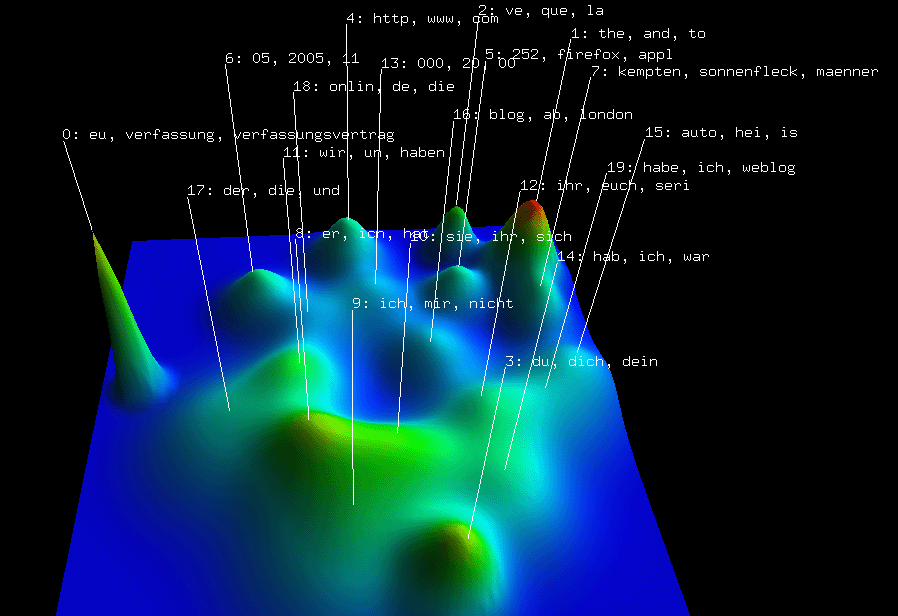
A SOM calculated on the twoday-survey data, with a 4x4 grid, and pre-ordered columns:
-> [pdf]

to provide an ‘‘executive summary’’ of a massive data set
by extracting the n most prominent patterns (where n is the
number of nodes in the geometry) and arranging them so that
similar patterns occur as neighbors in the SOM. As with all
exploratory data analysis tools, the use of SOMs involves
inspection of the data to extract insights.
SOMs are widely used in data mining because they have
many desirable mathematical properties, including scaling well
to large data sets. In our own hands, we have indeed found
them valuable in analyses involving hundreds of experiments.
A SOM calculated on the twoday-survey data, with a 4x4 grid, and pre-ordered columns:
michi - 4. Sep, 21:44




{kind=link}